How Machine Learning could impact the laboratory in the next decade
Since the first neural network prototype was developed in 1957, machine learning has undergone multiple hype and bust cycles (AI winter). Today, machine learning is being deployed to help researchers across many different industries, such as pharmaceutical R&D, oil and gas, and agricultural science to find meaning in the massive amounts of data being produced. While artificial intelligence (AI) is a broad term that applies to any intelligence displayed by machines or software, machine learning is a specific subset of AI. Unlike the strict rule-based programs under which most of the software operates, machine learning learns from input data, environment and feedback, and then generalizes them to produce intelligence. Informatics systems like Laboratory Information Management Systems (LIMS) provide machine learning algorithms with the high-quality data needed to drive meaningful insight.
Rules-driven systems use logic such as, if X, then do A, else if Y, then do B, but have an inherent limitation when the problem/solution size increase. For example, the human brain has no trouble classifying a 10 x 10 pixel black-and-white image, but standard programming logic would require 1.2 x 1030 lines of “if, then, else” to accomplish the same task. Scientific data (e.g., biomarkers, gene sequences, mass spectrometry and images) can be tens of thousands in dimensions. Machine learning overcomes the limitations of rule-based systems by building models from training data, and they can be deployed to solve complex classification/clustering problems with large data dimensions. Recently Google’s AI was able to exceed the prostate cancer diagnosis’ average accuracy of general pathologists (61% vs 70%). Machine learning has also been used in early prediction of conditions such as diabetes. Additionally, the Oil and Gas Authority (OGA) is also making use of AI with the United Kingdom’s first National Data Repository (NDR), launched in May 2019. The NDR uses AI to interpret the data within the repository to uncover new oil and gas prospects. AI is playing a critical role in the UK’s energy transition, with its reservoir and infrastructure data supporting carbon capture, usage, and storage projects. AI has had an impact in agricultural applications as well. For example, AGROSAVIA is connecting Thermo Scientific™ SampleManager LIMS™ software to IBM Watson to better understand soil conditions and help farmers improve crop yield.
The last decade has witnessed a resurgence of machine learning in the form of deep learning (DL) after being complemented by the explosion of data, availability in compute power (cloud and GPUs) and advancements in training algorithms and architectures. This time it feels like it is here to stay and make an unprecedented impact in all aspects of human life and society. Unlike earlier machine learning methods, deep learning with its more complex abstraction capabilities can not only generalize and apply learned knowledge for inferring, interpreting and classifying new data, but it can also generate original and novel work/solutions. Deep learning is already being used in crop sciences, oil and gas exploration and in the development of new drug candidates. It has the potential to significantly reduce time, risk, and money used to bring new products to the market.
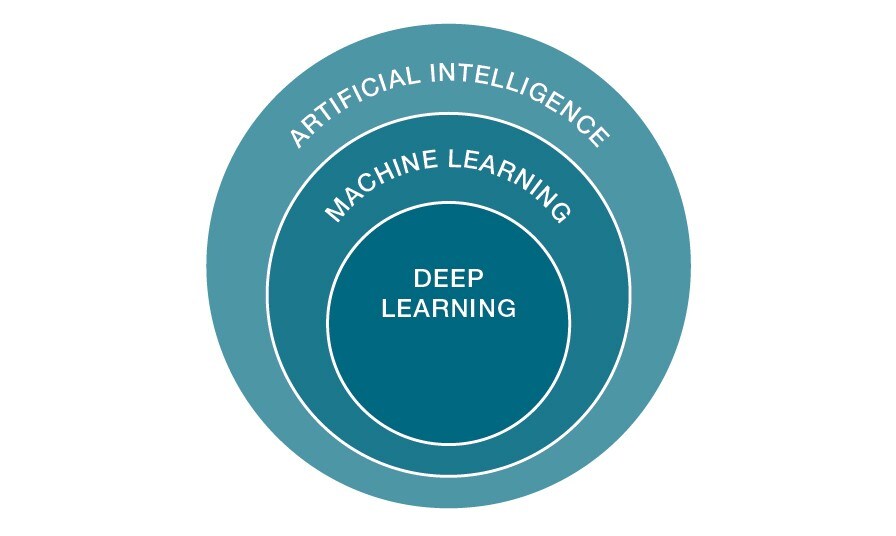
How AI, ML and DL relate to each other in a Venn diagram format
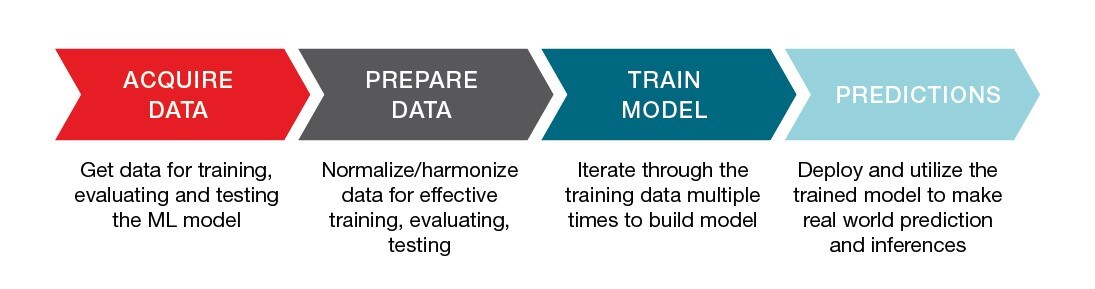
Machine Learning Consists of the following steps
In the last decade, the increase in speed of silicon-based computing has slowed down with the imminent death of Moore’s law, but we have witnessed remarkable growth in machine learning. AI has progressed from finding a cat in a video (2012), beating a world champion in the board game Go (Google/DeepMind’s AlphaGo, 2017) to proliferation of smart voice assistants (Amazon Alexa, Google Home, etc.), and applications in self-driving cars and cancer diagnosis, all using machine learning. In 2019, the three pioneers of deep learning (Yoshua Bengio, Geoffrey Hinton, and Yann LeCun) were awarded The Turing Award, which is referred to as the “Nobel Prize” in computing. Despite growth, we are far from human-level AI, which is commonly referred to as artificial general intelligence (AGI). While there are negative ways AI can be used (e.g., deep fakes), one area where it can make a positive impact is pharmaceutical research. Human biology lends itself very well to computation. While we have made strides in last few decades with genome sequencing and relationship mapping between genes, phenotype data, and clinical diagnosis/outcomes, the sheer size of biological data (e.g., over 3 billion nucleotides in the human genome) makes it impossible for rule-based systems to analyze and provide insights. Machine learning is an appropriate tool to address this and is already contributing to disease diagnosis/prediction and drug design/discovery. With AI getting more interest and funding from industry and prioritization from governments, its impact on healthcare is only expected to exponentially accelerate in the next decade.
LIMS is a powerful tool for the management of laboratory operations, but it is also a central solution that aggregates all of the laboratory data and metadata into a central location. LIMS with the use of a Scientific Data Management System (SDMS) directly takes the raw data generated from laboratory instrumentation, such as the Ion Torrent™ Ion Chef™ instrument and stores that data in a central repository. Modern LIMS utilize an Application Programming Interface (API) to communicate between various software systems, including the communication between LIMS and data lakes. The data that was directly captured by the LIMS provides a direct mechanism enabling AI to mine through high-quality data to make meaningful insights. This blog is the first in a series detailing how Thermo Fisher software applications can support the use of advanced digital technologies, such as AI, to accelerate science.


Lab of the Future Conference 2025: How the Digital Automated Lab, AI, and Orchestration Are Accelerating Science
Setting the stage In the heart of Amsterdam, the Beurs van ... Mark Fish
Read More
Thermo Fisher Scientific Recognized as a Star Player in Lab Informatics by MarketsandMarkets’ 360Quadrants
Laboratory informatics solutions are essential for lab users...
Read More
Benefits of Implementing a Laboratory Information Management System
Evaluating laboratory operations with advanced LIMS software...
Read More
Insightful article on LIMS system and its prospective growth in the industry. With the immense amount of data we have to work with, an online LIMS system (cloud-based) could be helpful with data management and collaborations. Artificial intelligence and machine learning can help process data faster to meet industry specs.